内容简介
IBM的一些存储产品
- DS8000
- 双控制器,每个控制器是一个中低端的Power服务器
- 主要部件包含CEC, IO Enclosure, Storage Enclosure, Power Supply, Batteries
- 其中IO Enclosure包含连接主机光纤卡(Host Adapter)和连接磁盘柜的设备卡(Device Adapter)
- 磁盘柜里是硬盘或者是固态盘
- 是为数不多的同时支持CKD和FB(fixed block)的存储。目前更多的作为大机的外部存储。
- XIV
- IBM收购的一家以色列初创公司,创始人是Moshe Yanai. 公开资料显示他是EMC Symmetrix的负责人。创了XIV后,离开了IBM, 又创了Infinidat这家公司,最近被联想收购,这是后话。
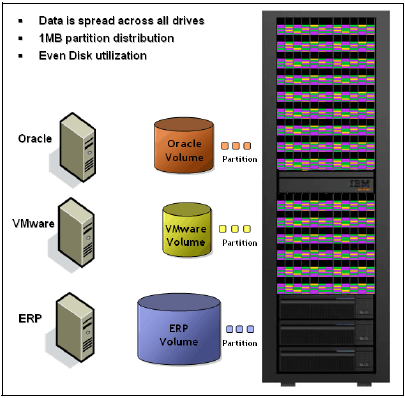
- 网格架构的存储
- 客户的数据分两份, 数据的存放粒度是1MB大小的块,分别存放在不同的控制器内部的磁盘柜内
- 平均分布在所有的节点上
- 相对于当时的企业级传统存储有一定的优势,解决了一些过去传统存储的痛点,比如管理更简单,无性能热点,数据重构快等
- A9000
- XIV的继承者
- 全闪存阵列,后端使用FS900
- 包含快照,复制和Active-Active等高级功能
- 产品价值在于有了压缩和去重,宣传可以达到5:1的可用容量和裸容量的比率;使得全闪存阵列更有性价比
- 当时的市场热点是闪存阵列,如何解决容量和价格的矛盾。有些产品使用分层技术,有些产品使用压缩和去重的技术。
- 竞品是XtremIO,后被EMC收购.
- 后续IBM做了战略调整,缩小产品线,使用Spec-v架构的存储替代了XIV架构的存储
- FS900
- IBM收购的一家全闪存公司TMS的第三代产品。Texas Memory Systems是一家比较早做闪存存储的公司。
- 两个控制器
- 全闪存阵列,阵列的保护级别为2D RAID-5 (就是在一张卡的芯片级别和多张卡之间做了两层的RAID保护)
- 主要用于对于响应延迟有极致要求的应用场景
- 缺少如快照,复制等高级功能
- 可以单独使用,也做为A9000以及V9000的后端存储使用
- 后续的部分技术应该是用在了spec-v系列存储的后端
存储的基本功能和一些高级特性
SAN存储的基本功能是提供一些fixed block device, 又叫LUN. 这里的fixed block的意思是每个block的大小是固定的。
每个block的大小是512 bytes,是为了和过去的标准兼容。每个block都有一个地址,叫做LBA(logical block address)。
对于主机来说就是被分配了一块某个大小的块设备,然后主机按照LBA地址来对这个设备进行访问。如果去研究SCSI的命令,你就可以发现
比如首先SCSI命令分READ/WRITE. 然后命令的一些参数就包含了LBA地址和所需要读写数量等信息。而后台存储可以做很多事情,比如:
- 高可靠性: 各种各样的RAID保护级别,比如RAID-0(条带化,提高性能),RAID-1, RAID-5, RAID-6, DRAID-6等等
- 高可用性: 两个或者多个控制器,保证某一个控制器坏掉或者需要做维护时,主机可以通过其他控制器访问数据
- 虚拟化: 由于数据具体放在哪里完全有存储决定,所以存储可以做一些文章,比如可以做精简配置(thin provision),冷热数据自动分层等
- 缓存: 缓存大部分是存储控制器的内存,早期也有放在固态盘里,可以提高性能。通常写缓存需要写2份或者更多份,保证单个控制器损坏不会导致数据丢失。电池容量的大小决定了写缓存的大小
- 分层: 利用虚拟化的技术,热数据在固态盘,冷数据在硬盘
- 压缩: inline compression, 主要是指数据在写入后端存储之前就在内存中进行压缩
- 去重: 同样内容的数据只保留一份,比如在A9000的实现中,对8KB的主机写数据计算Hash,然后比较是否有重复数据。
- 快照: 通常有COW和ROW等不同的实现,各有一些优缺点
- COW (copy on write)
- ROW (redirect on write)
- 数据同步: 同步复制和异步复制
- active-active: 两地存储提供高可用性,主机通过多路径软件的ALUA功能访问本地站点存储
存储在设计的时候就考虑了高可靠性,但是...
这个世界不是完美的。一些SAN存储的问题包括:
不同产品所使用的RAID保护级别和一些问题
DS8900F 支持如下RAID级别
- 5+P+Q+S RAID6
- 6+P+Q RAID6
- 3+3+2S RAID10
- 4+4 RAID10
- 5+P+S RAID5
- 7+P RAID5
看上去一个array只能支持8块盘。这就带来一个问题,如果一个array里的一块盘坏了需要重构,那么能参与数据重构的盘只有7块。随着
硬盘越来越大,重构所需要的时间也会变得很长。重构的时间变长也是一个风险隐患点。红皮书里也有提到:
RAID 6 arrays are created by default on each array site. RAID 10 is
optional for all flash drive sizes. RAID 5 is optional for flash drives smaller than 1 TB, but is not
recommended, and requires risk acceptance.
在数据重构的时候发生第二块硬盘故障的事件在客户现场也偶有发生。DS8000的应对方式是采用RAID6. 让我们看看其他存储是如何应对的
Spec-V系列存储
比如FS5100推荐使用distributed raid6
In a traditional RAID approach, data is spread among drives in an array. However, the spare
space is constituted by spare drives, which sit outside of the array. Spare drives are idling,
and do not share I/O load that comes to an array. When one of the drives within the array fails,
all data is read from the mirrored copy (for RAID10), or is calculated from remaining data
stripes and parity (for RAID5 or RAID6), and written to a single spare drive.
In distributed RAID, spare capacity is used instead of the idle spare drives from a traditional
RAID. The spare capacity is spread across the disk drives. Because no drives are idling, all
drives contribute to array performance. In case of drive failure, the rebuild load is distributed
across multiple drives. By this, distributed RAID addresses two main disadvantages of a
traditional RAID approach: it reduces rebuild times by eliminating the bottleneck of one drive,
and increases array performance by increasing the number of drives sharing the workload.
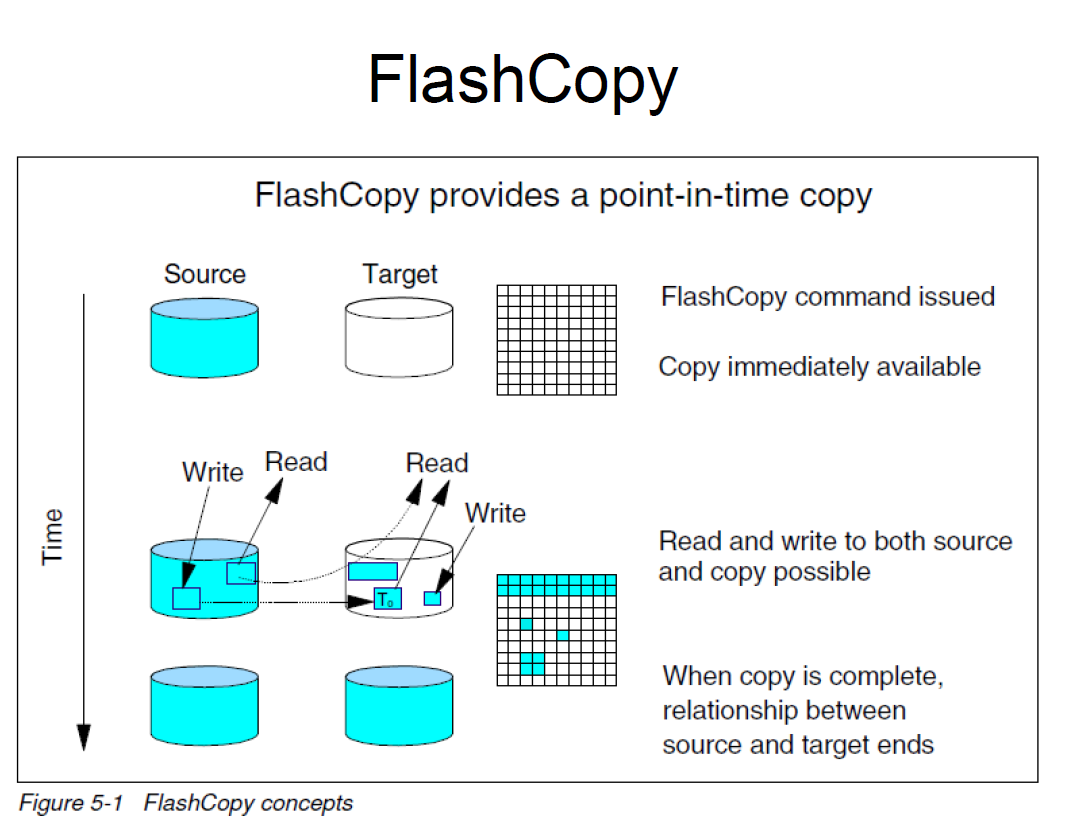
XIV的数据保护
XIV采取一种相对比较简单的方式。它定义数据的存放单位是1MB大小的区块(XIV的术语是partition). 每一个客户数据卷以RAID1 mirror的形式均匀的分布在系统所有的硬盘上。
这样的好处是,如果有任何一个硬盘故障,所有的其他磁盘会参与数据重构,这会大大加快数据重构的速度。减少数据没有冗余的时间窗口。当然这样的设计也带来一些质疑:
如果同时有两块盘失效,或者一块盘失效,在数据重构是另外一个盘也出现了问题,系统会如何应对。
我们先考虑第二种情况:当第一块硬盘发生故障,数据开始重构。在重构的过程中,第二块磁盘也发生故障。这个时候XIV会去尝试从第一块磁盘读取第二块磁盘无法访问的数据。
因为在实际场景中,磁盘完全不能访问的情况很少见。更多的情况只是某些区域无法访问,或者是由于超过了某些预设定的数值而系统自动将第一块盘踢出系统,此时第一块盘并没有完全损坏。
这种情况下一般是不会有数据丢失的。
只有在某些极端的情况下,确实有发生过两块盘完全不能访问的情况,特别是运行时间很长的机器,经历了关机开机,甚至搬迁,这个时候发生的多块盘报错的情况的风险比较高。发生这种情况就比较痛苦了,需要判断数据损失的范围,考虑从备份中恢复。
在数据重构的时候发生第二块盘损坏会发生什么
通常存储会告警
- DS8000会报告kill sector
- XIV会报告suspect data loss
当这个发生时,我认为主机可能能感知,也可能感知不到这样的情况发生。取决于主机访问的数据是否落在不可重构的部分,以及存储是
如何应对这样的问题的。
比如我自己碰到的一个AIX LVM的mirror重构(类似于存储的RAID-1重构数据) 碰到第二块盘也报错的情况,此时文件系统会进入只读模式。
换盘时的注意点:
当我们需要给存储设备更换硬盘时,需要知道此时的RAID状态是什么样子的。正常情况下存储的RAID应该是完成了重构。取决于不同的产品,可能定义的状态名称不一样
需要查相应的手册确认存储的阵列是否已经完成了重构。比如A9000的一些状态:
- fully protected
- redundant, missing spare
- unprotected, rebuilding
- unprotected
静默数据损坏(silent corruption)
什么是静默数据损坏:
数据写入后,下次读取时可能读取的内容和当初写入的内容不一致。
这种情况也很难发现,因为你已经不清楚之前写入的数据是什么。通常在应用层可能会有一些校验,比如数据库的一些文件头部,或者日志文件有校验可以检测到这类的问题。
但是仅仅发现数据损坏并不能解决问题,比如恢复数据。企业级存储可能有端对端的数据校验能力,比如我们看看DS8000是如何应对的
- DS8000
对于每一个512-byte block, DS8000都有校验块。每次读取数据的时候都会去校验数据和校验块的信息是否一致
DS8000 A4 adapter 的设计文档提到
LBA-seeded LRC detects data corruption in drive or in cache.
注意这个和RAID保护是没有关系的。在一个正常的读的IO路径里,RAID 校验是不会检查的。只有在数据重构的时候才会需要用RAID的校验位来重构数据。
工业界也有标准T10 DIF Support来支持端对端的数据校验。
- XIV
相对来说XIV应对这类问题就有点不足。XIV应对这个问题主要是通过后台数据扫描(data scrubber)。后台数据扫描的简单机制如下
- read a partition
- on success, try to locate the secondary partition (the mirror pair) and if also on success, compare the checksum on both partition to verity if they
are the same. in case there is a mismatch, an event SCRUBBING_CHECKSUM_DIFF will emit. If the system is configured call home, it will automatically report a case to IBM to require further investigation.
- if the partition read is not successful, e.g. a medium error is countered during the read, the scurbber will attempt to read the secondary partition
of the data and if on success, write the recovered data locally.
- if the read of the secondary partition is also not successful, issue the SUSPECT_DATA_LOSS event, which actually means there is a data loss.
so in fact the XIV storage has several chances in very early stage to find and fix potential data loss situation, with a simple RAID1 mirror.
案例分享: XIV静默数据损坏导致DB2 crash,无法正常启动
一家金融客户,客户的环境非常的典型
- 两台AIX主机形成一个PowerHA Cluster
- DB2数据库使用的是共享存储。共享存储卷是在XIV上
- 是一个生产环境。业务主要是做银行的短信通知
以下是一个发生故障的时间节点
Day 1, 2:58
XIV的后台扫描程序检测到一块硬盘突然报SCRUBBING_CHECKSUM_DIFF. 在6:14分以后停止报错。这个行为不太正常
Day 1, 5:00 AM
客户管理员被通知到发生了一些故障。客户管理员发现db2 instance没有启动。
重启数据库服务不起作用,报错: "log file encounterred during recovery has checksum errors"
Day 1, 7:30
在重启数据库未果,短期内无法解决数据库服务启动的问题, 客户决定使用另外一套后端存储,从备份中恢复
Day 1, 10:30 -- 11:30
数据库恢复完成,业务完成验证,业务开始逐步恢复
Day 2 and Day 3
客户希望知道db2 instance无法启动的原因,遂决定搭建一套新的主机,使用原来的存储来检查原因
Day 4
这次确认数据库服务可以启动。无法重现问题。
技术讨论
整个事件主机和数据库应该都是受害者。数据库检测到checksum error. 大概率是存储提供的数据有误,没有通过数据库的数据校验。
由于存储实际上对于主机和上层应用是一个黑盒子,主机和数据库在修复层面也很难有所作为。
根据存储后台研发人员的分析,大概率是这样的: 首先存储从磁盘中读取数据到cache中,整个读取的过程没有报错,但我们怀疑读入的数据是空的,很有可能是磁盘的微码bug导致的。
但XIV当时没有一些检测机制,导致这个空的数据返回给了主机,那么上层的应用没法忍受这种错误,自然就crash,或者无法启动。
后续存储会增加一层保护机制,预先格式化内存区域为特殊标签,比如DEADBEEF. 然后读取数据后做一个检查,如果内存区域的数据仍旧是DEADBEEF, 则
证明数据未被正确从磁盘中读取,后续在做进一步的正确的反应。
在这次事件中,因为是一个临时性的问题,过了几个小时以后,data scrubber没有继续报错,而且后续客户要求的厂商做进一步分析也因为无法重现问题而告终,间接证明是一个临时性的错误.
解决问题比较简单,更换故障硬盘,升级微码。但这个也证明企业级存储在数据校验方面需要有更高的要求。
一些存储产品的微码升级过程简介
- 从CDAInstallationhistory了解DS8000的微码升级过程
DATE MTMS PACKAGE MODE BUNDLE VRMF PACKAGE LEVEL
================ ==================== ========== ===== ============ =============
2009/10/24-14:00 7978PEN*KDKXXXX HMC N 64.21.18.0 N/A
2009/10/25-10:49 9117-570*75BXXXX Squadrons D 64.21.18.0 01SF240_355_201
2009/10/25-11:03 9117-570*75BXXXX-V1 AIX_ML C 64.21.18.0 5.3.7.0
2009/10/25-11:03 9117-570*75BXXXX-V1 AIX_PTF C 64.21.18.0 5.3.7.115
2009/10/25-11:03 9117-570*75BXXXX-V1 SEA.sfi C 64.21.18.0 5.4.21.280
2009/10/25-11:38 9117-570*75BYYYY Squadrons D 64.21.18.0 01SF240_355_201
2009/10/25-11:53 9117-570*75BYYYY-V1 AIX_ML C 64.21.18.0 5.3.7.0
2009/10/25-11:53 9117-570*75BYYYY-V1 AIX_PTF C 64.21.18.0 5.3.7.115
2009/10/25-11:53 9117-570*75BYYYY-V1 SEA.sfi C 64.21.18.0 5.4.21.280
2009/10/25-12:40 2107-932*75VXXYY SEA.ha C 64.21.18.0 5.4.21.280
2009/10/25-12:57 2107-932*75VXXYY SEA.se C 64.21.18.0 5.4.21.280
2009/10/25-13:14 2107-932*75VXXYY RPC0 C 64.21.18.0 VER00064
2009/10/25-13:14 2107-932*75VXXYY RPC1 C 64.21.18.0 VER00064
2009/10/25-13:16 2107-932*75VXXYY PPS0 C 64.21.18.0 VER00064
2009/10/25-13:24 2107-932*75VXXYY PPS1 C 64.21.18.0 VER00064
2009/10/25-13:24 2107-932*75VXXYY Power C 64.21.18.0 VER00064
从时间戳可以知道这是一个很久以前的升级。希望DS8000的架构没有发生大的变化. 从升级的日志可以了解到是先升级
FSP微码,然后是操作系统AIX_ML和AIX_PTF, 然后是存储的微码SEA.sfi. 再然后就是做一次切换,然后继续升级另外一个CEC的微码。
完成两个CEC的微码升级后,继续升级host adapter和storage enclosure的微码,然后升级电源相关的微码,比如RPC, PPS。
整个升级的过程非常的冗长。应该以及做了很多的改进,现代的DS8000微码升级应该不需要这么旧的时间。在做host adapter的微码升级的时候应该会对主机的访问
有一个短暂的影响,但主机一般都配置多路径软件,可能只会出现短暂链路切换的告警。
- FS900的微码升级过程.
FS900是一款全闪存的存储,有部分的管理代码和spec-v系列的存储通用,所以升级的过程也和spec-v系列的存储有类似的地方
the code upgrade process is as follows. note that there is a control path and data path. so upgrading components relating to control path has no impact to the data path.
- the active svc manager in canister 1 upgrades the remote svc manager in canister 2
- the svc manager cluster moves the active node to canister 2, the new svc manager upgrades the remote svc manager in canister 1
- upgrade battery in canister 1
- upgrade battery in canister 2
- upgrade the spare flash card
- upgrade all active flash cards; this results in a data path stall up to 4 seconds
- upgrade xbar in canister 1
- upgrade xbar in canister 2
- upgrade interfaces in canister 1, may take 30 minutes for detection and on-lining
- upgrade interfaces in canister 2
即便是在线升级,在升级HA的微码的时候,还是会等待30分钟使得主机有足够的时间可以让多路径软件稳定下来。
注意它的升级过程分为control path和data path;
先升级control path的部分,再升级data path的部分。
- XIV/A9000 的微码升级过程
XIV/A9000 use kexec to load new code without cold reboot
XIV的微码升级过程和上述存储产品有所不同。在升级的过程中是所有的控制器一起升级,利用一种叫Kexec的机制去加载Linux Kenel 而无需冷重启.
这就带来一个挑战,需要在最长30秒之内恢复IO访问。
案例分享: A9000微码升级引发了应用down
主机看到的hdisk的配置信息:
hdisk0 U9080.MHE.XXXXXXX-V26-C7-T1-W5001738054610130-L1000000000000 MPIO 2810 XIV Disk round_robin Queue Depth:40 XIV:31872 S/N:88888
hdisk1 U9080.MHE.XXXXXXX-V26-C7-T1-W5001738054610130-L2000000000000 MPIO 2810 XIV Disk round_robin Queue Depth:40 XIV:31872 S/N:88888
hdisk2 U9080.MHE.XXXXXXX-V26-C7-T1-W5001738054610130-L3000000000000 MPIO 2810 XIV Disk round_robin Queue Depth:40 XIV:31872 S/N:88888
hdisk3 U9080.MHE.XXXXXXX-V26-C7-T1-W5001738054610130-L4000000000000 MPIO 2810 XIV Disk round_robin Queue Depth:40 XIV:31872 S/N:88888
hdisk4 U9080.MHE.XXXXXXX-V26-C8-T1-W5001738054610192-L5000000000000 MPIO 2810 XIV Disk round_robin Queue Depth:40 XIV:31872 S/N:88888
hdisk5 U9080.MHE.XXXXXXX-V26-C8-T1-W5001738054610192-L6000000000000 MPIO 2810 XIV Disk round_robin Queue Depth:40 XIV:31872 S/N:88888
从主机端ndc3vpaieaiapp54看到的errpt的输出:
Mar 1 23:40:20 fscsi7 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x281000; cmd element included
Mar 1 23:40:20 fscsi3 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x281100; cmd element included
另外一个主机ndc3vpaieaiapp55看到的errpt的信息:
Mar 1 23:40:21 fscsi4 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x1E2200; cmd element included
Mar 1 23:40:20 fscsi5 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x282000; cmd element included
Mar 1 23:40:20 fscsi4 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x1E2200; cmd element included
Mar 1 23:40:20 fscsi6 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x283000; cmd element included
Mar 1 23:40:20 fscsi5 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x282000; cmd element included
Mar 1 23:40:20 fscsi2 T FCP_ERR12 Data overrun reported in FCP response IU from port 0x1E1300; cmd element included
从存储端确认de-couple的时间在30秒以内。基本符合设计要求
2019/03/01 23:40:20.601955 kernel info nextra-7888888-module-1 [1594540.727583] i_node[2377]: hot_upgrade_progress: Blocking target layer, is_decouple_in_progress 0
2019/03/01 23:40:20.601982 kernel info nextra-7888888-module-1 [1594540.727641] i_node[2377]: hot_upgrade_progress: dispatching port_block (worker 1)
2019/03/01 23:40:49.624765 kernel info nextra-7888888-module-1 [ 19.932145] manager[1872]: hot_upgrade_progress: time_to_give_up updated to 1362899771981814, current time is 1362899768751369, decouple_duration is 28769547, i_node: 1001
2019/03/01 23:40:51.136667 kernel info nextra-7888888-module-1 [ 21.444587] i_node[1629]: hot_upgrade_progress: IOs restored. decouple start time: 1551463820601989, total time: 30282510us
客户报告有一个Messaging APP 在23:40停止了,并且据客户反映导致了数据的损坏,客户只能从备份中恢复业务。从存储看一切都是正常的。
即便从AIX的层面看,也只是有一些临时性的报错。结论是客户的业务程序需要做更健壮一些,可以忍受长达30秒的IO延迟。
XIV这样的设计微码升级过程已经在不同的客户环境里经历了几千次的验证。像这种极少数的业务影响案例只能从业务端去做一些改进。
或者在一些比较空闲的窗口去安排微码升级是一个比较安全的选择
存储性能问题的讨论
性能问题非常的宽泛,比如是响应时长太长,还是带宽不足,是部分主机有问题还是所有的主机都有问题?
下面是几个存储性能相关的问题需要收集的一些信息,通常也非常冗长,但也是对于快速定位问题很有帮助。
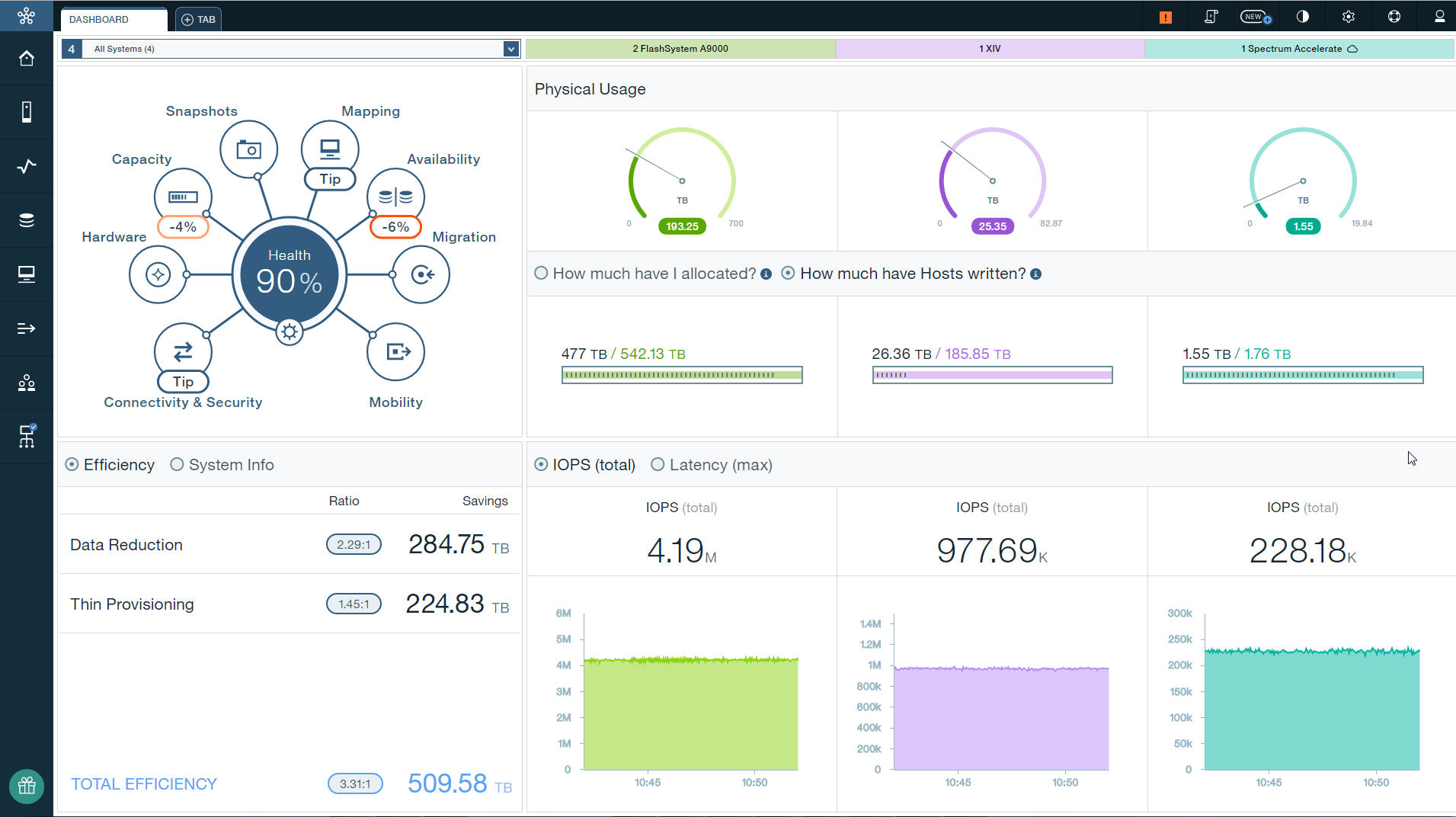
- 最简单,最直观的方法是通过GUI来显示当前的性能图标,比如IOPS, latency和bandwidth. 下面的例子可以看到两台A9000存储可以达到4M IOPS. 一台XIV可以达到接近1M IOPS,
spectrum Accelerate(纯软件定义存储),可以达到22万IOPS。都是一些漂亮的数据,我估计可能读的占比会高一些。
- 如果没有GUI直观的展示性能图表,通常需要收集性能数据,通常是csv格式的数据。根据这个数据做一些可视化的分析。
- 现代存储已经在设计上做了很多优化,传统存储的性能调优,寻找热点的思路可能已经不太合适
- 如果是突然发现性能有很大的下降,并且是大多数主机都有下降,考虑存储是否有一些硬件故障和由于硬件故障的不及时正确处理导致的系统响应缓慢。就是前面提到的
sick-but-not-dead 的情景。
- 如果只是少部分主机有性能瓶颈,思路应该是尽可能的通过多路径或者是并行的方式来增大业务压力。
- A9000 FC卡的一些参数:
- buffers per FC adapter port: 1400
- queue depth per mapped volume per I_T_L Nexus 256
- 现代的存储产品通常的性能都很好,很少有业务能够达到甚至超过存储自己的限制。随着存储产品越来越智能,可以调整的参数也越来越少。
比如XIV A9000的设计思路就是尽可能的使用系统所有的资源来满足性能要求。更多的时候只是需要主机侧尽可能的通过多条路径和业务的并行方式来
释放更多的压力。